
只要字母加得够粗,你就追不上我的阅读速度
先来个测试:下图有左右两段英文文本,分别阅读它们并感知一下自己阅读这两段文本的速度,读左侧时比较快?还是右侧比较快?
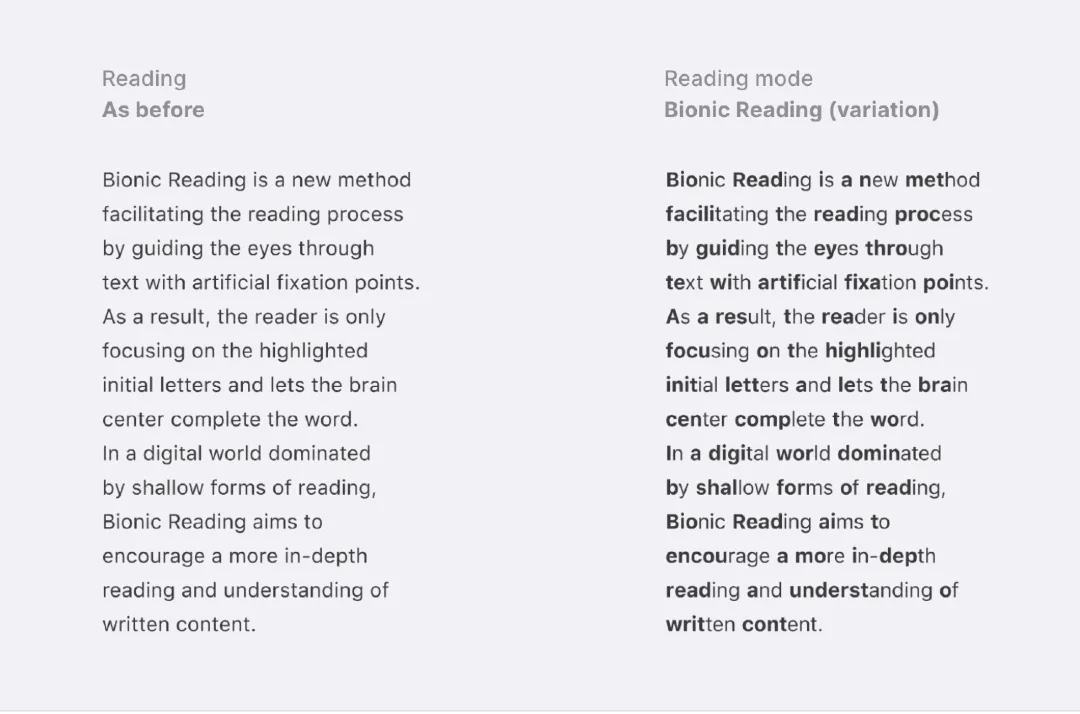
就许多外国网友的测试结果看来,许多人都认为右侧文本的阅读速度更快,或者说给文本中的单词首字母大写或者加粗的操作能够提升阅读速度,仿佛是“100%释放了大脑的潜能”。
当同样的文本测试给到我们,同样也有不少人认为右侧文本的特殊处理能够有效提高阅读速度。



这难道不是所有英语学习者/应用者的福音吗?阅读英文原版内容从此就是小菜一碟,先打住——
然而,我们每个人的主观感受并不能证明英文文本的单词首字母大写或者加粗的变形与提升阅读速度二者存在因果关系。
首先,两段测试文本的内容一致,先读完左侧再读右侧本身就存在重复,需要通过进一步在实验中通过抵消平衡法(ABBA法)控制这一变量、克服练习效应。其次,还存在许多干扰变量,如每一个人的英语词汇量有多有少,有的人选择朗读、有的人选择默读,阅读时周围环境有的安静、有的吵杂等等。
当然,这也不全毫无道理,其实是从业生涯足足有25年的瑞典排版设计师Renato Casutt偶然发现的一种技术,被他称为仿生阅读(Bionic Reading)。

下面就来好好说说,仿生阅读其中到底有什么奥秘呢?如何才能为人们所用、有效提升英文阅读速度或者应用到其他方面呢?

其实刚才的测试文本就是Renato Casutt给出的仿生阅读概念(翻译如下):仿生阅读是一种新型的阅读方法,通过人为定点引导人眼浏览文本,从而促进阅读过程。如此一来,在阅读的时候,读者只关注到高光的首字母并让大脑补全单词。在一个浅阅读占主导的数字世界里,仿生阅读的目的是鼓励更多的深度阅读和对书面内容的理解。
研究阅读方法本不是Renato Casutt这个排版设计师的工作,但排版设计工作确实也与优化文本接收、处理字体等方面息息相关。在一次偶然的机会下,当时还是学生的Renato Casutt在为某个瑞士畅销书作家的书做设计时,由于这本书不是用标准德语所撰写的,他在阅读上有很大的难度,但是当作家头口跟他描述这本书的内容,长期生活在瑞士的他也能多少理解一些口语上的表达。
*冷知识:瑞士分为四个语区,分别是德语区、法语区、意大利语区、罗曼什语区。
借由这个契机,Renato Casutt意识到了,大脑其实仅需几个熟悉的单词就推测出其他陌生语句的意义,进而理解整个文本。而对于对于他身边那些本身就十分熟悉瑞士德语的同学而言,这个规律能让他们提升阅读速度,这便是仿生阅读的雏形。
尽管仿生阅读的官网没有披露具体的实验和数据,但根据其概念的两个关键点——“引导人眼的定点”、“大脑补全单词”但不难猜到这与认知心理学等相关学科有着极大的关系。
早在1980年,视线固定和阅读速度的相关性已经被心理学研究者注意到了,学者Just与Carpenter提出了一个阅读理解模型,该模型解释了14名大学生在阅读科学文献时的目光注视分配会因文本的量级而异。简而言之。当学生在处理量更大的内容时,看一整篇文章和看一个从句、几个单词相比,会花更长的时间;当学生在处理不常用的单词、整理从句中的重要信息时也需要更长的时间。

Underwood等人在1990年的研究记录了读者在30秒内眼睛读取句子的眼球运动,结果显示视线固定和阅读速度有更密切的关系。据实验结果的判别分析,视线固定的持续时间能预测读者的阅读理解,读的时间长了能够加深对文本的理解程度。更重要的是,同样是这个实验的多元回归分析显示,阅读速度会受到视线固定的句子数量、持续时间以及平均持续时间的影响。
而大脑之所以能够在眼睛只注视到几个字母就能快速完成整个单词的理解,是基于知识经验在知觉中的作用。
心理学家Warren等人在1970年的音素恢复实验的扩展实验中,当他们给予实验被试聆听发音残缺(*号部分)的句子,并让被试补充残缺的部分时,「It was found that the *eel was on the shoe」这句话往往会因为句末的「shoe」而被「heel」补全,「It was found that the *eel was on the orange」这句话会因为「orange」而倾向于被「peel」补全……此种恢复现象是人的知识、经验储备作用的结果,依赖于现实刺激对策信息和已经贮存信息的相互作用,不仅作用在语言的发音,阅读文本、辨认图像也有类似的表现。

另外,心理学家Reed在1973年提出的模式识别的模型也能佐证“大脑补全”现象。
Reed认为,“模式识别是从特征分析开始的。模式的各个成分即特征先得到确认,然后模式各部分的关系再得到确认……特征和关系的结合就形成了对模式的解释。” 在仿生阅读中,被高光的字母可以是视作是“特征”,而这些字母和单词的“关系”往往前缀或者词根的体现,当特征和关系完整地解释了这个模式,也就是说在人们的脑海中眼下被强调的字母(特征)直接匹配上记忆所储存的整个词汇(模式),减少信息接收与识别的时间。
下面这个理论也许能更容易被理解——字词优势效应(Word-Superiority Effect),心理学家Reicher在1969年的实验中发现,识别单词中的某个字母的正确率要高于单独识别某个字母的现象。后来也有许多心理学家的实验也验证了字词优势效应的存在,对此有许多受到较广泛认可的解释,其中有一个“编码说”似乎也能解释仿生阅读的原理。“编码说”认为,单词是语音编码的,单个字母是视觉编码的。因此仿生阅读利用识别单词中的加粗字母来提高阅读速度借助的就是字母在单词存在的语音编码,而不是单个字母共同组合的视觉编码。
综上所述,对字体进行高光的形式利用视线固定节省了阅读和理解的时间,而选择高光部分字母则是因为知觉的模式识别有赖于经验储存、编码信息加工特点。
除了以上这些来自心理学、语言学的研究和理论,相信Renato Casutt以及他的仿生阅读机构也进行了大量的实验和研究,也向许多测试、试用过的用户收集到了许多反馈,想必会更符合如今读者的阅读实际情况。

据仿生阅读的官网所示,仿生阅读的好处有很多,包括但不仅限于节省时间、减少注意力分散,能更快地学习新事物,扩展知识面,对个人和集体而言都是极大的革新性进步。
官网还提供了一个转换器(https://api.bionic-reading.com/convert/),每个人都可以把任意的英文文本放进去,如论文、新闻报道等,便能自动生成仿生阅读模式,大大提高学习、工作效率,还可以自定义自己偏好的字体、大小、行距、不透明度等格式。
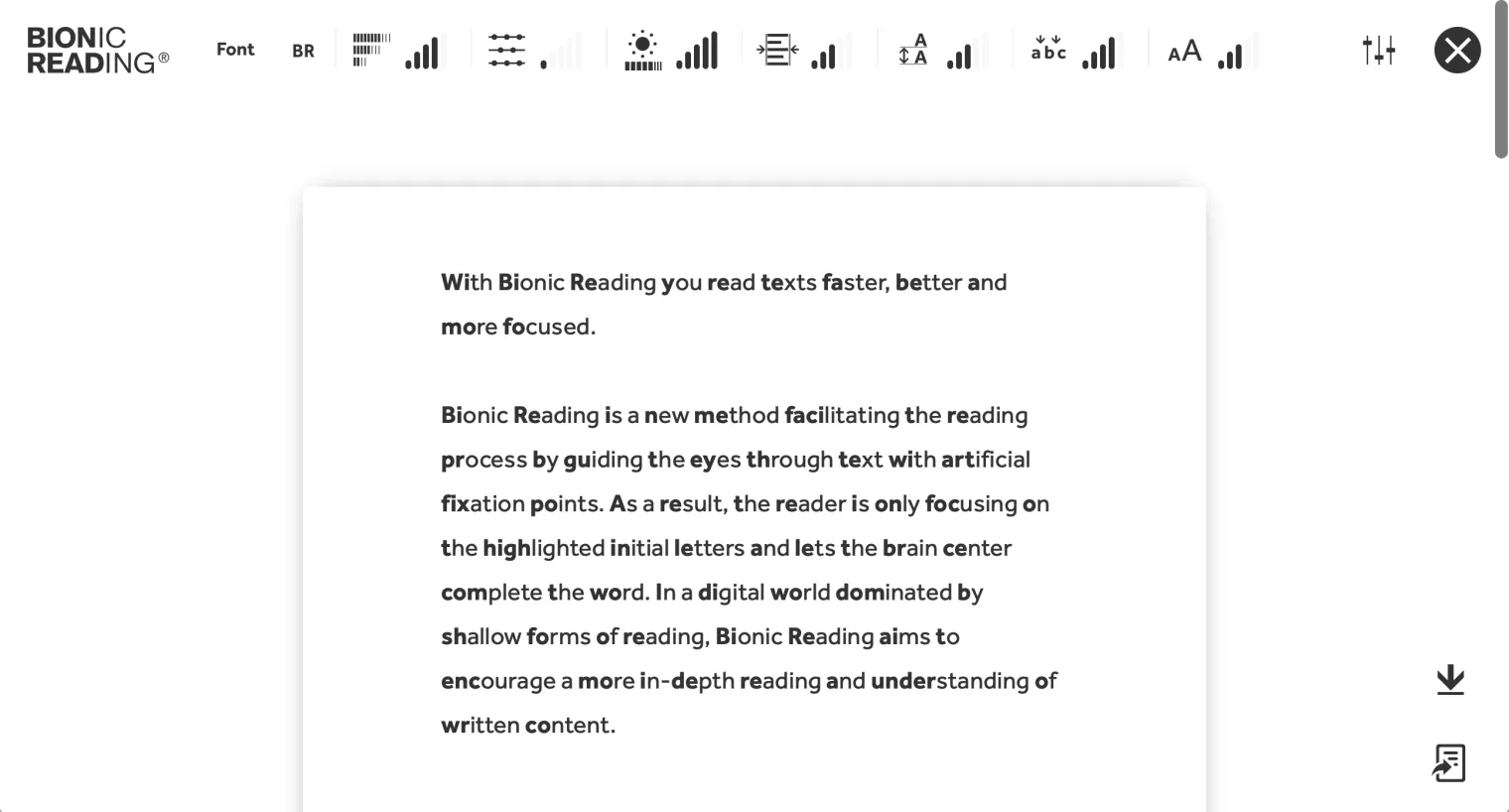
而对于软件开发人员、设计师而言,官网提供的仿生阅读器API还能够供他们运用到各种程序开发中,如浏览器,阅读、新闻类app的开发设计等,期待将来能在更多的地方享受到仿生阅读的好处,惠及更多英语使用者。
以上关于仿生阅读的讨论范围是在英语这门语言中,我不禁想,中文或其他语言是否也有类似的语言学特点可发展出仿生阅读的技术呢?说不定是外语学习、教育类应用研发市场的下一个财富密码。
参考文献:
1.Just, M. A., & Carpenter, P. A. (1980). A theory of reading: From eye fixations to comprehension. Psychological Review, 87(4), 329–354.
2.Underwood, G., Hubbard, A., & Wilkinson, H. P. (1990). Eye fixations predict reading comprehension: The relationships between reading skill, reading speed, and visual inspection. Language and Speech, 33(1), 69–81.
3.王甦,汪安圣. 认知心理学. 北京大学出版社, 2006年版, 39页, 65页



